[ Android Opengl es 2.0 ] LoadTexture
[ Android Opengl es 2.0 ] 화면 전체 이동 및 회전
OpenGL | ES 튜토리얼 6편
[안드로이드]ndk란?
인공지능에 자주 나오는 수학 4 - 유사 계수(Similar Coefficient)
인공지능에 자주나오는 수학 2 - 벡터 공간(Vector Space)과 벡터 내적(Vector InnerProduct)
인공지능에 자주나오는 수학 1 - 유클리디안 거리(Euclidean Distance)
인공지능에 자주 나오는 수학 3 - 맨하탄 거리(Manhattan Distance)
TSR Workshop
obj viewer 구현 및 정리
시소당
인공지능에 자주나오는 수학 2 - 벡터 공간(Vector Space)과 벡터 내적(Vector InnerProduct)
인공지능에 자주나오는 수학 2 - 벡터 공간(Vector Space)과 벡터 내적(Vector InnerProduct)
벡터 공간(Vector Space)이란 용어가 전산논문에 자주 나옵니다.
모든 벡터들이 (x,y) 같이 두개의 좌표로 표현 가능하다면 2차원이므로 벡터 평면이라고 하구요.
(x,y,z)와 같이 3개 이상의 좌표로 방향을 표현 할 수 있는 경우 3차원 이상이므로 벡터 공간이라고 합니다.
뭐 어려운 이야긴 아니죠? 그래도 Vector Space라고 하면 쫌 뽀대나는 용어같아요.
벡터 공간 이야기가 나오면 대부분 벡터 내적에 대한 이야기가 따라 나오는데...
벡터 공간에서 벡터의 내적은 두 벡터간의 유사도를 수치화 하기 위해 주로 사용됩니다.
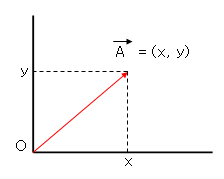
요건 벡터 평면
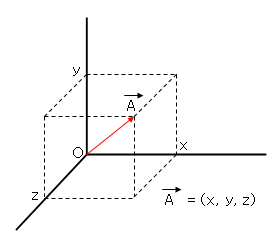
요건 벡터공간 (글쓰기 보다 그림 그리기가 더 어렵네요.
벡터의 내적은 외적인 X기호와 구별하기 위해 다음과 같이 표기 합니다.
자 이제 기본 공식을 볼까요?
여기서 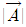 라고 표시되는 부분은 해당 벡터의 노름(Norm)이라는 것으로 해당 Vector의 크기를 의미합니다.
라고 표시되는 부분은 해당 벡터의 노름(Norm)이라는 것으로 해당 Vector의 크기를 의미합니다.
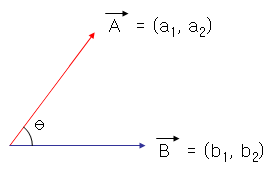
위의 그림에서 벡터A의 노름은 빨간 선분의 길이에 해당됩니다.
노름의 계산은 다음과 같이 할 수 있습니다.
이게 바로 "인공지능에 자주 나오는 수학 1"에서 이야기한 벡터 A의 점과 원 (0,0)과의 거리를 제는 유클리드 공식 아니겠습니까? (갑자기 뿌듯...)
위의 벡터 공식을 코사인 제이법칙을 써서 어떻게 어떻게 풀면 다음과 같은 공식이 또 도출 됩니다.
(뭐 제가 수학을 가르칠려고 하는 건 아니니깐... 이해 바랍니다.)
처음 말한 내적 공식은 cosθ 떄문에 뭐 값을 계산하기 어렵지만 위의 공식은 계산이 가능하겠네요.
자 이제 두 내적 공식을 이용하면 다음과 같이 정리 하여 cosθ 값을 알아낼 수 있습니다.
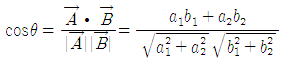
여기까지가 제가 이야기 하고자 하는 벡터 스페이스 공식의 다 입니다.
자 이제부터 이 벡터 내적 공식으로 유사도를 어떻게 알아낼 수 있다는 것인지 설명하도록 하겠습니다.
사실 벡터의 내적을 이용한 유사도 측정이 이번 강좌에서 설명하고자 하는 본질이니깐요.
두 벡터가 얼마나 유사한가는 두 벡터의 좌표를 이용하여 전에 이야기 했던 유클리디안 거리 측정으로도 할 수 있습니다.
하지만 이는 벡터의 성질을 이용한 것이 아니죠.
벡터의 성질을 이용한 유사도 측정 방법으로 가장 많이 사용되는 방법은 cosθ값을 활용하는 방법입니다.
아시다 시피 cos 함수의 성질은 θ의 값이 0도 이면 1, 90도 이면 0값을 갖게 됩니다.
각도가 90도 보다 좀 더 벌어지면 음수값으로 바꾸고 270도가 넘으면 다시 양수로 바꾸면서 -1 ~ 1 사이의 값을 갖습니다.
자 여기서 cosθ 값이 0도 이면 두 벡터가 가장 가깝게 되고 그 값은 1이 됩니다. 180도가 된다면 두 벡터가 가장 멀리 있게 되어 -1 값을 갖게 됩니다.
이런 이유로 단순히 cosθ 값 만 가지고도 유사도를 측정할 수 있습니다.
또 좋은 점 중에 하나는 유사도가 cos함수의 성질 때문에 -1 ~ 1 값 만을 갖기 때문에 다른 벡터와의 유사도를 서로 비교할 때 최대값과 최저값을 알고 있기에 계산이 훨씬 쉽습니다.
하지만 이는 벡터의 성질을 이용한 것이 아니죠.
벡터의 성질을 이용한 유사도 측정 방법으로 가장 많이 사용되는 방법은 cosθ값을 활용하는 방법입니다.
아시다 시피 cos 함수의 성질은 θ의 값이 0도 이면 1, 90도 이면 0값을 갖게 됩니다.
각도가 90도 보다 좀 더 벌어지면 음수값으로 바꾸고 270도가 넘으면 다시 양수로 바꾸면서 -1 ~ 1 사이의 값을 갖습니다.
자 여기서 cosθ 값이 0도 이면 두 벡터가 가장 가깝게 되고 그 값은 1이 됩니다. 180도가 된다면 두 벡터가 가장 멀리 있게 되어 -1 값을 갖게 됩니다.
이런 이유로 단순히 cosθ 값 만 가지고도 유사도를 측정할 수 있습니다.
또 좋은 점 중에 하나는 유사도가 cos함수의 성질 때문에 -1 ~ 1 값 만을 갖기 때문에 다른 벡터와의 유사도를 서로 비교할 때 최대값과 최저값을 알고 있기에 계산이 훨씬 쉽습니다.
cosθ값을 이용하여 유사도를 측정하는 것이 나름 합리적으로 보일지는 모르지만 한가지 문제 점이 있습니다.
이는 벡터의 노름(Norm)을 유사도 계산시 고려하지 않는 다는 것 입니다.
아래의 그림을 보면 두 벡터의 사잇각은 같지만 두 벡터의 거리는 많이 차이가 남을 알 수 있습니다.
이는 벡터의 노름(Norm)을 유사도 계산시 고려하지 않는 다는 것 입니다.
아래의 그림을 보면 두 벡터의 사잇각은 같지만 두 벡터의 거리는 많이 차이가 남을 알 수 있습니다.
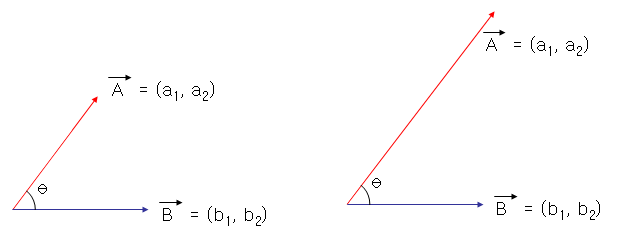
그래서 이를 보완하기 위해서 하나의 벡터를 또 다른 벡터에 투영하여 얻어진 길이를 유사도로 사용합니다.
여기서 투영한 길이라는 말이 잘 안와 닫는다면 그냥 두 벡터 위에 전등을 비춰 위에 있는 벡터의 그림자가 아래에 있는 벡터에 생겼을 때 그 그림자의 길이라고 생각하시면 됩니다.
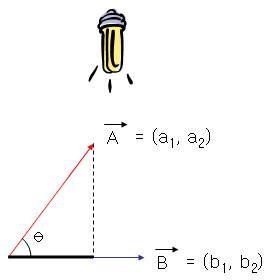
만약 두 벡터의 크기가 같다면 θ값이 0도이면 두개의 벡터가 딱 맞다아 있어 그림자도 벡터의 벡터 A의 길이와 같을 거구요. (그림자 중 가장 길겠죠?)
θ값이 90도라면 두 벡터가 직각이 되어 그림자가 하나도 생기지 않을 것입니다. (그림자 중 가장 잛을 것 입니다.)
그럼 이 그림자의 길이를 어떻게 구하면 되는가가 문제가 되겠네요.
위의 그림에서 보면 직각 삼각형이 그려진 것을 볼 수 있습니다.
아시다 싶이 직각 삼각형에서 cosθ는 밑변을 빗변으로 나눈 값입니다.
이를 삼각비라고 하죠?
이 식을 조금만 정리하면 밑변은 cosθ 값과 빗변을 곱한 값이 되겠죠.
즉, 위의 그림에서 그림자에 해당하는 밑변의 길이는 다음과 같이 구할 수 있습니다.
우리는 이미 공부한 내용에 의해 벡터 A의 노름값도 구할 수 있고 cosθ값도 구할 수 있으니 뭐 그냥 계산만 하면 되겠네요.
아무튼 이런 식으로 두 벡터의 유사도를 측정할 수 있습니다. 그런데...cosθ의 값은 -1~1까지의 값을 갖게 되어 계산이 편리했는데... 이 투영한 길이를 제는 방식은 0 ~ 벡터의 길이 까지의 범위를 갖게되어 좀 불편합니다. 그래서 투영한 벡터의 길이와 그 그림자가 생긴 벡터의 길이를 1로 한 비율로 계산을 해 내면 0~1사의 값을 갖게 되어 좋습니다.
글이 길어질 것 같아 설명 안한 것이 하나 있는데...
유사도를 계산하기 위해 사용되는 방법 중 또 다른 하나는 벡터의 합을 이용하는 것입니다.
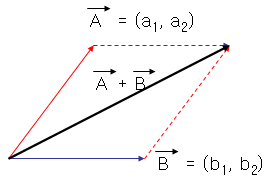
두 벡터의 합은 두 벡터를 이용해 그린 평행 사변형의 대각선 벡터와 같습니다.
이것 역시 각이 좁으면 길어지고 각이 넓어지면 짧아지는 성질이 있습니다.
이에 대해서는 위의 투영된 벡터의 길이와 내용이 유사 함으로 여러분이 직접 생각해 보세요.
참고로 두 벡터의 합 벡터는 다음과 같이 만들 수 있습니다.
위와 같이 벡터의 합이 좌표로 나오면 길이(노름)를 계산하는 건 위에서 이미 이야기 했죠?
사용예
"인공지능에 자주 나오는 수학 1"에서 이야기한 유클리디안 거리 공식으로 유사를 구했던 문제를 다시 벡터의 내적으로 풀어보도록 하겠습니다.
문제를 다시 적는다면 다음과 같습니다.
예를 들어 세개의 문서가 있고 각 문서는 a, b, c, d라는 단어로만 구성되어 있다고 합시다.
1번 문서는 a가 3번 b가 2번 c가 0번 d가 2번 출현했다고 하고
2번 문서는 a가 1번 b가 2번 c가 3번 d가 0번 출현했다고 하고
3번 문서는 a가 2번 b가 2번 c가 2번 d가 2번 출현했다고 하면
각 단어의 출현빈도를 속성으로 갖는 문서 D1을 정의하면 다음과 같이 정의할 수 있습니다.
D1 = { 3, 2, 0, 2 }
D2 = { 1, 2, 3, 0 }
D3 = { 2, 2, 2, 2 }
질의: "a가 1번 b 5번 나온 문서와 가장 가까운(유사한) 문서는?"
전에와 같이 질의두 다음과 같이 표현하여 벡터 내적을 적용하면 될 것 같네요.
Q = {1, 5, 0 , 0}
예를 들어 세개의 문서가 있고 각 문서는 a, b, c, d라는 단어로만 구성되어 있다고 합시다.
1번 문서는 a가 3번 b가 2번 c가 0번 d가 2번 출현했다고 하고
2번 문서는 a가 1번 b가 2번 c가 3번 d가 0번 출현했다고 하고
3번 문서는 a가 2번 b가 2번 c가 2번 d가 2번 출현했다고 하면
각 단어의 출현빈도를 속성으로 갖는 문서 D1을 정의하면 다음과 같이 정의할 수 있습니다.
D1 = { 3, 2, 0, 2 }
D2 = { 1, 2, 3, 0 }
D3 = { 2, 2, 2, 2 }
질의: "a가 1번 b 5번 나온 문서와 가장 가까운(유사한) 문서는?"
전에와 같이 질의두 다음과 같이 표현하여 벡터 내적을 적용하면 될 것 같네요.
Q = {1, 5, 0 , 0}
이미 이야기한 대로 두가지 방법으로 이를 풀 수 있겠죠?
풀이1) 첫번째 방법은 벡터 Q와 다른 문서 벡터와의 사잇각 θ를 이용하기 위해 cosθ 값을 구해서 비교하는 것입니다. (문제를 생각하고 만든게 아니여서 풀다 보니깐... 소수점 이하가 너무 길네요. 대충 소수점 4번째 자리에서 반올림하여 적겠습니다.
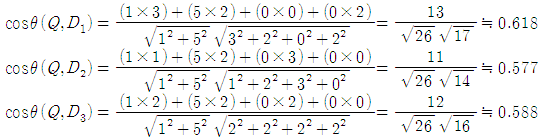
cosθ 값을 구해 봤더니 벡터 사이의 각이 가장 좁은 것은 D1임을 알았습니다.
이 방법으로는 D1이 질의와 가장 비슷한 문서네요.
풀이2) 두번째 방법은 벡터 Q를 문서 벡터에 투영하여 그 길이를 문서 벡터의 길이의 비를 구해서 비교하는 것입니다.
벡터 Q가 벡터 D1, D2, D3에 투영된 길이를 각각 R1, R2, R3이라고 하면 다음과 같이 계산 할 수 있습니다.
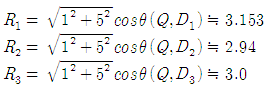
이 계산된 값은 제각각의 길이를 갖고 있으므로 서로 비교하기가 힘들기에 각각 문서 벡터의 길이를 1로 하여 비율을 계산하면 다음과 같습니다.
비율은 각각 r1, r2, r3 로 표시하겠습니다.
비율은 각각 r1, r2, r3 로 표시하겠습니다.
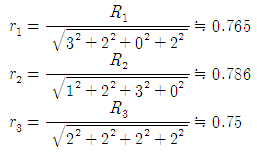
여기까지 계산하고 나니깐... 재미있게도(?) 질의와 가장 유사한 문서는 D2로 바뀌어 버렸네요.
거의 값들이 비슷 비슷해서 나타나는 현상이기도 하고 cosθ값이 노름에 대해 반영하지 못한 결과이기도 합니다.
이런 결과가 나올거라면 뭐하러 cosθ값으로 유사도를 검사했냐고 물으실 수도 있겠네요.
물론 벡터의 노름까지 처리를 하도록 하면 좀 더 정확한 건 사실이지만 데이터의 성격 상 단위 벡터로만 벡터들이 생성된 다거나 노름의 의미 자체가 별로 중요하지 않고 대용량의 데이터를 처리해야 하는 경우 계산의 빠르게 하기위해 cosθ값만을 사용할 수 있기 때문입니다.
자 이번 벡터 공간과 벡터 내적에 대한 강의는 여기까지 하겠습니다.
참고로 인터넷에서 찾은 삼각함수 곡선 관련 그림입니다. (삼각함수라는 것을 가시적으로 볼 수 있어 좋네요.)
저는 http://blog.naver.com/jangbalam99?Redirect=Log&logNo=10029491008 에서 찾아서 그림을 옮겨 왔는데... 아마 이분도 다른데서 스크랩한 것 같습니다.
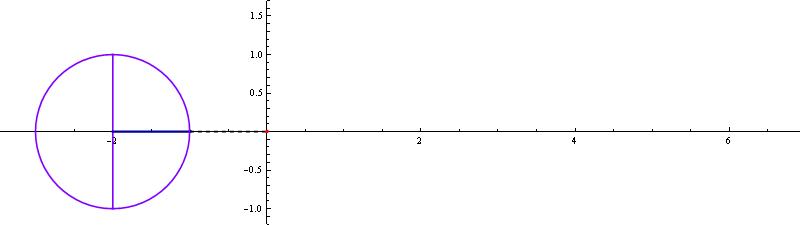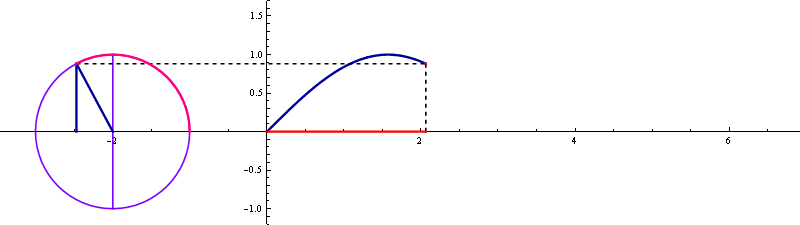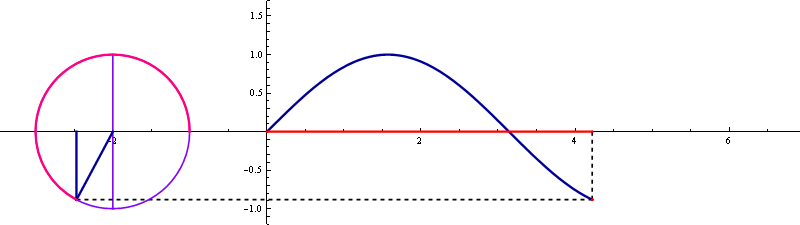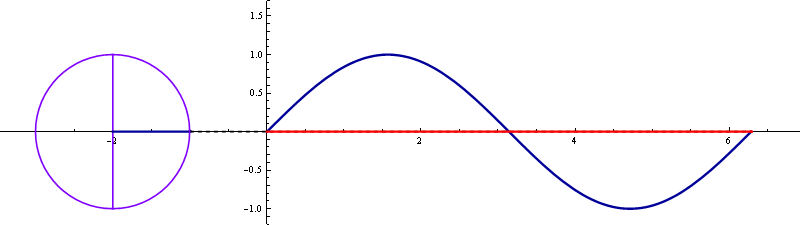
▲ sin 곡선
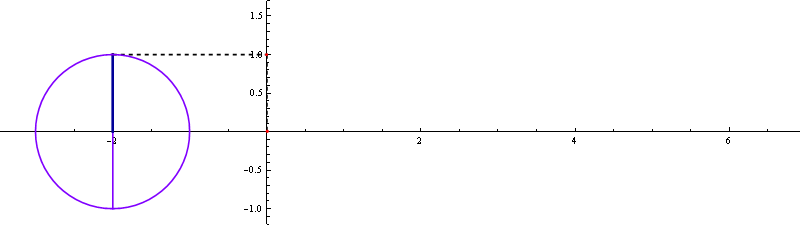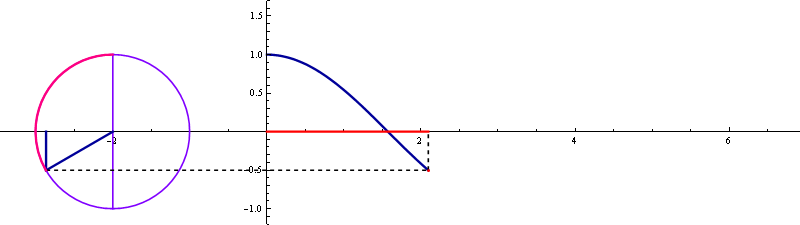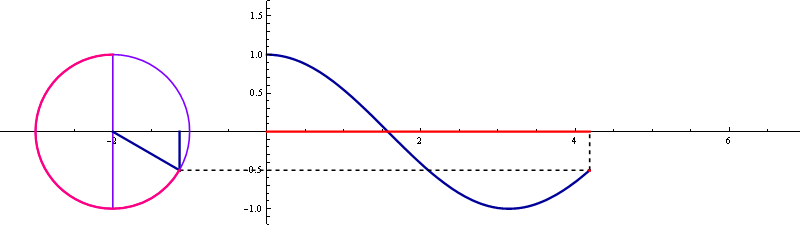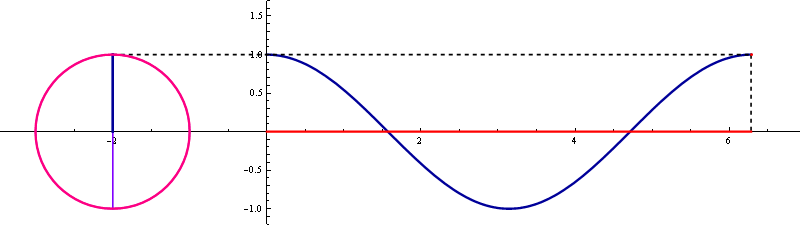
cos 곡선
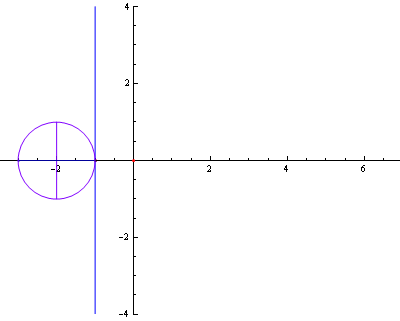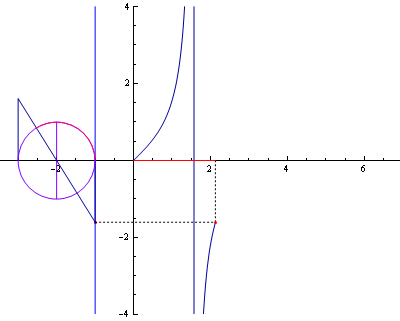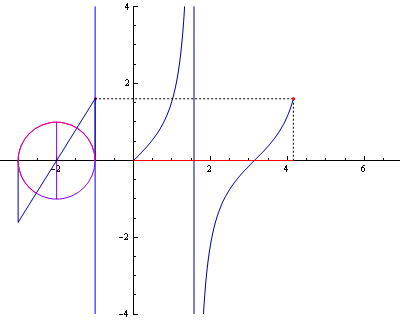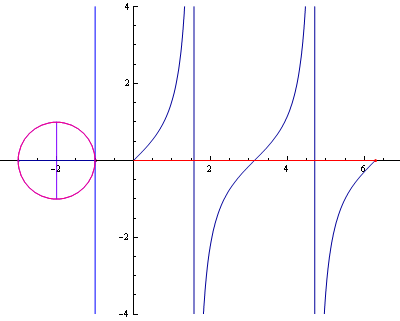
▲ tan 곡선
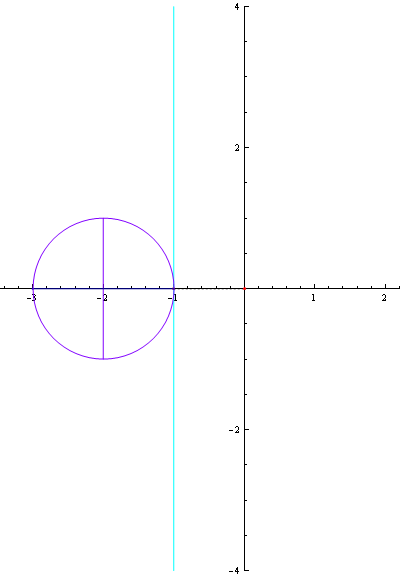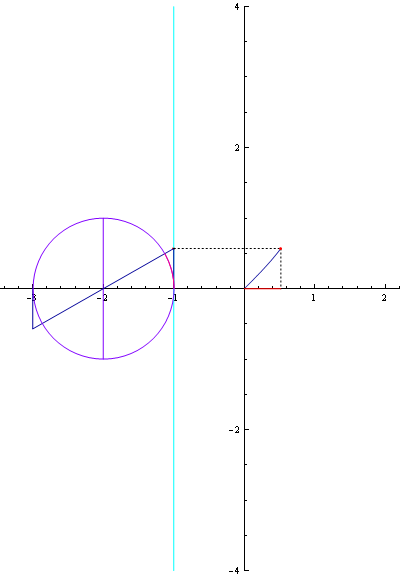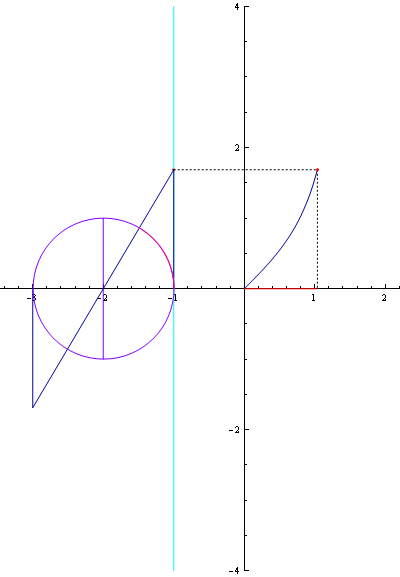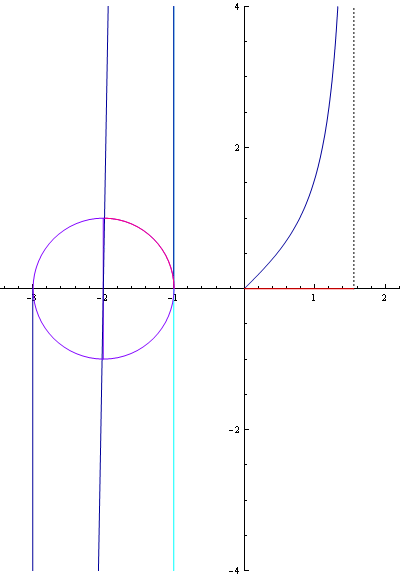
▲ tan 곡선 자세히 보기
★ Reference
SSISO Community
[ Android Opengl es 2.0 ] LoadTexture
[ Android Opengl es 2.0 ] 화면 전체 이동 및 회전
OpenGL | ES 튜토리얼 6편
[안드로이드]ndk란?
인공지능에 자주 나오는 수학 4 - 유사 계수(Similar Coefficient)
인공지능에 자주나오는 수학 2 - 벡터 공간(Vector Space)과 벡터 내적(Vector InnerProduct)
인공지능에 자주나오는 수학 1 - 유클리디안 거리(Euclidean Distance)
인공지능에 자주 나오는 수학 3 - 맨하탄 거리(Manhattan Distance)
TSR Workshop
obj viewer 구현 및 정리